
This went down the rabbit hole and then around the corner. It wasn't a success in the sense that I succeeded, but it was a great journey.
I tried many new approaches, but actually didn't upgrade the physical robot at all except to add a 'pusher' out of three bamboo skewers. It looks ridiculous, which only isn't embarrassing when it works. ( foreshadowing )

This time around I wanted to train my vision models from the ground up, and also give object detection a try. I chose to go with tensorflow and keras. I generated tens of thousands more thumbnail-sized images of a cube randomly placed on a tabletop. I imagined and trained some more classifiers that I thought would help.
The challenge became optimizing my models for filesize and inference cost, while preserving accuracy. Its kind of one of those 'triangle-tradeoff' situations.
If filesize and inference cost were no object then it was easy to get 98%+ accuracy, but whittling the network down to something reasonable for the ESP32 made it hard to get an F1 score above 0.92.
The first phase used https://eloquentarduino.com/posts/micro-mobilenet . Ultimately through a ton of experimentation with tflite and quantization I was able to produce some tiny models.
~/projects/tablebot_two$ du -h data/*
8.0K data/corners_pure_v3.tflite
8.0K data/dangernet_pure_v1.tflite
152K data/edgenet_pure_v1.tflite
8.0K data/leftright_pure_v1.tflite
156K data/object_v3.tflite


Tangents
Since this is primarily a learning project I let my imagination wander and I started to dabble in a lot of things that caught my attention.
Going on a tangent with a Gazebo simulation - the collision/interaction with the block itself was something I wanted to understand. I learned all about URDF and SDF formats for defining robots in code.

I considered behavioral conditioning, recording 'episodes' driven by a human then training on those episodes. temporal component of this got too complex

I also thought about switching from using a camera to a TOF sensor that would give an 8x8 grid of distance values. I got this completely simulated in Gazebo and ready to start generating training data ... when I decided to come back to the original creative restrictions. I want to make as many inferences as possible from a single sensor
It will still be a challenge adding an object detection model to the mix
Again I simulated training data with a python script randomizing positions, textures, lighting, all within the domain of the simulated scene. This time I left out the creepy people standing around and stuck with lots of chairs to help randomize the backgrounds ( the background of what I want the model to focus on )

Control Design
In retrospect I didn't leave enough time for this part of the project.
One of the nicer-looking byproducts of this project was this diagram. I used Obsidian's 'canvas' mode.
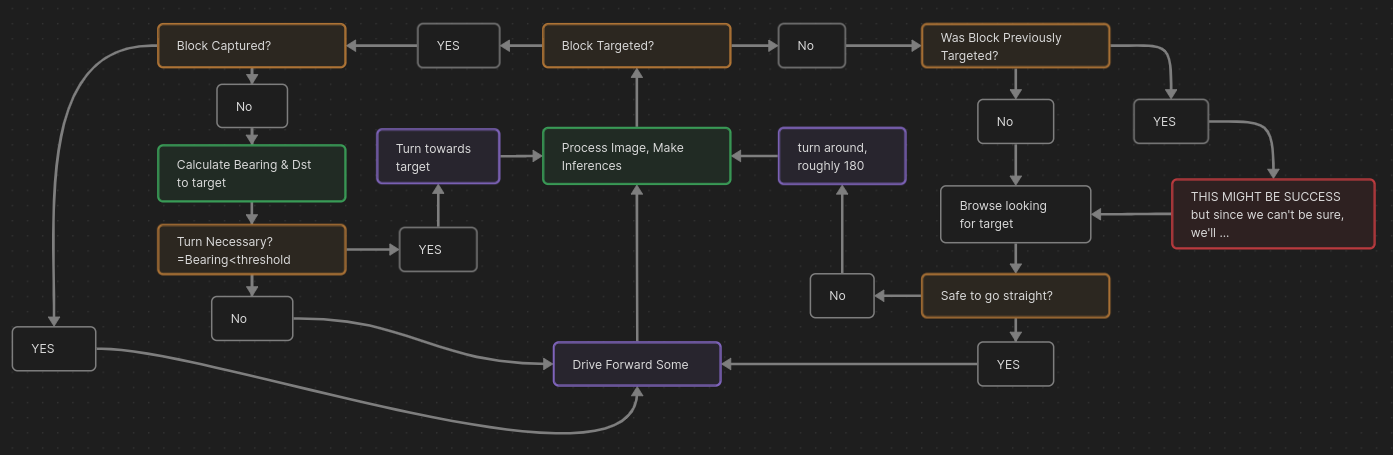
This process of mapping the inference outputs to navigation behaviors was fun. It wasn't as simple to combine the two goals as I had expected.
The biggest challenge was the poor performance of the vision models in real life. In order to keep things moving ( literally ) I would only capture a single image at a given position and then make a navigation decision, turning or driving significantly between each capture. It would have performed better with more inferences and smaller strides, but it also would have been painfully slow to demonstrate.
This is a visualization of the object-detector's prediction

The Result
June 25th rolled around quickly and I was still tweaking things the day-of. I could tell that the image-classifying models were performing decently, but the logic I had cooked up to synthesize their results and turn it into navigation wasn't working.
The real performance-hog was the object-detecting model. At 900ms-per-inference you can see why navigating is so slow. I needed this inference to determine heading to the target, but it would have probably worked better to model this as another classifier: "target on left, target on right"
Basically, it didn't go very well.

You can watch the full video below, but its painful.
This repository is the actual robot part, not all the image generation and model training:
https://github.com/anthonyrobertson/tablebot-two
Conclusions
This is both a failure and a success. I'll have to repeat the challenge and will probably rethink some of my choices, but this was a very fruitful learning experience.
One thing I could have done ( as I learned others do ) is train my model to recognize a more distinctive block, like one of a specific color. That would have probably amplified my accuracy and would possibly be easier to do with traditional image-processing techniques.
Next time I might pivot away from using computer vision. I've already moved on to exploring the TOF sensor idea.

